anti-oom-processor
Anti-OOM Processor
![]()
Engine de processamento de CSV de alta performance projetada para lidar com arquivos de múltiplos gigabytes com consumo de memória baixo e constante. Utilizando Node.js Streams e Backpressure, previne falhas de “Out-of-Memory” (OOM) comuns em implementações ingênuas.
💥 O Problema: “Funciona na minha máquina”
Um cenário comum em backends Node.js:
- O Marketing faz upload de um arquivo
produtos.csv(500MB, 2 milhões de linhas). - O servidor tenta ler o arquivo inteiro na memória RAM (
fs.readFile). - Resultado:
FATAL ERROR: Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap out of memory. O servidor trava e derruba todas as conexões ativas.
Este projeto resolve isso tratando os dados como um Fluxo (Flow), e não como um Bloco.
✨ Demo
🌊 Arquitetura e Fluxo de Dados
flowchart LR
Client[Upload do Cliente]
filesys[Busboy Stream]
parser[CSV Parser]
batcher[Processador em Lote]
db[(MongoDB)]
Client -->|Stream MultiPart| filesys
filesys -->|Pipe| parser
parser -->|Linha a Linha| batcher
subgraph Protecao de Memoria [Node.js Pipeline]
direction TB
batcher -- "Buffer Cheio (1k linhas)" --> db
db -. "Ack (Backpressure)" .-> batcher
batcher -. "Pausar Leitura" .-> parser
end
Conceitos Técnicos Chave:
- Backpressure: O sistema pausa automaticamente a leitura do arquivo se a escrita no banco de dados ficar lenta. O uso de RAM nunca dispara porque os dados “esperam” no disco/rede, não no heap.
- Stream Pipeline: Usa
stream.pipelinepara garantir limpeza correta e tratamento de erros. Se a requisição for abortada, a stream do arquivo fecha imediatamente. - Processamento em Lote (Batch): Em vez de inserir 1 linha por vez (problema N+1), agrupamos linhas em chunks de 1000 e realizamos operações
bulkWrite, aumentando o Throughput em ~50x.
🛠 Tech Stack
- Runtime: Node.js 20+ / TypeScript
- Framework: Fastify (Baixo Overhead)
- Libs de Streaming:
@fastify/multipart(Wrapper do Busboy)csv-parse(Parser compatível com Streams)
- Banco de Dados: MongoDB + Mongoose (Bulk Operations)
- Observabilidade:
- Log de Uso de Memória (Heartbeat)
- Server-Sent Events (SSE) para Progresso Visual em Tempo Real
🚀 Como Rodar (Quick Start)
1. Requisitos
- Node.js 18+
- MongoDB (Local ou Atlas)
2. Instalar Dependências
npm install
3. Executar Localmente
# Iniciar MongoDB (se usar Docker)
docker-compose up -d
# Iniciar Aplicação
npm run dev
4. Testar com Arquivo Grande
Em vez de buscar manualmente um CSV gigante, utilize os scripts inclusos para gerar e enviar um arquivo de teste.
A. Gerar CSV de 100MB
npx ts-node scripts/generate-csv.ts
Cria o arquivo large_file.csv na raiz do projeto (100MB).
B. Upload via Stream para o Servidor
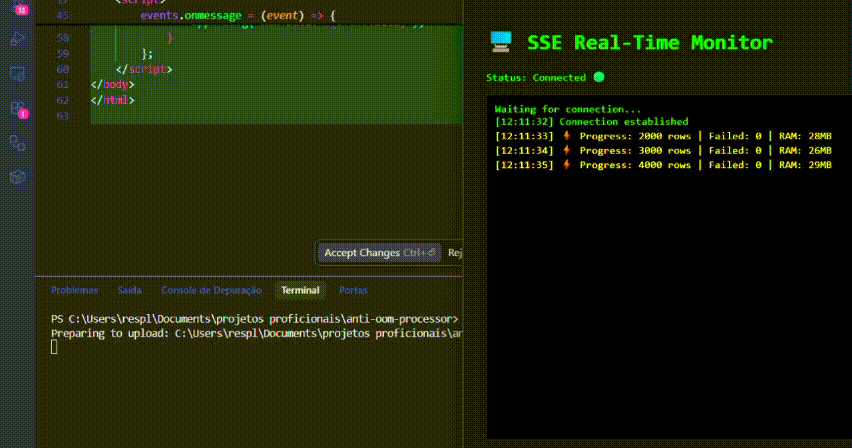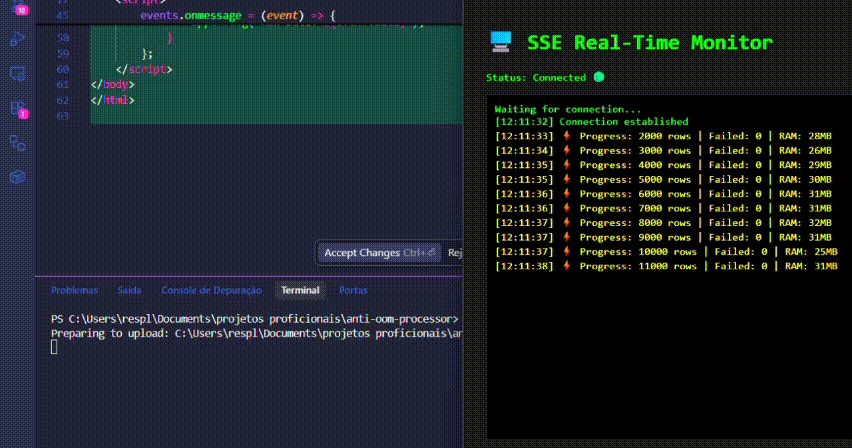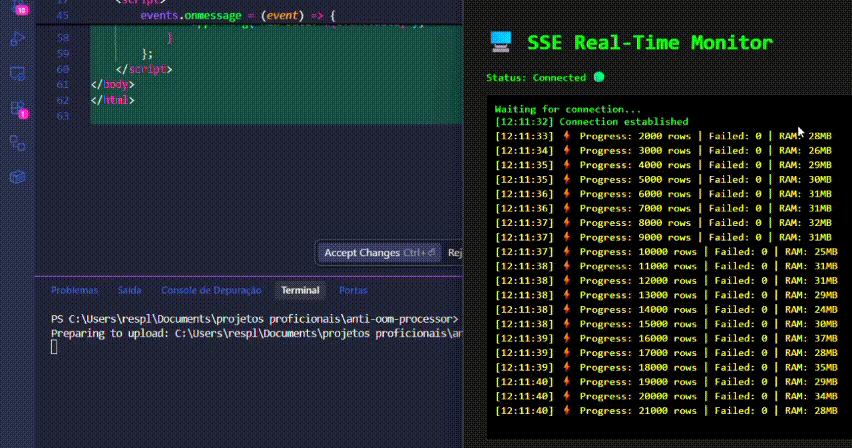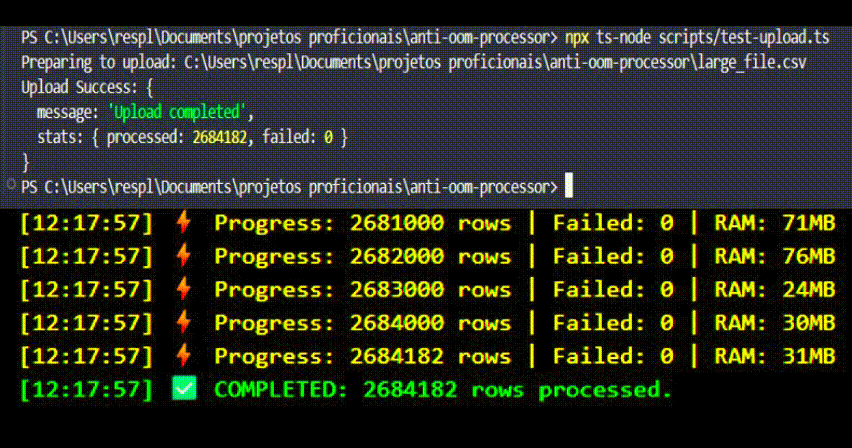
npx ts-node scripts/test-upload.ts
Este script faz o streaming do arquivo (prevenindo OOM no cliente) e loga a resposta do servidor.
Observe os Logs:
[Progress] Processed: 10000 | Failed: 0 | Heap: 42MB
[Progress] Processed: 20000 | Failed: 0 | Heap: 43MB <-- Memória Estável!
5. Dashboard em Tempo Real (Demo SSE)
Para visualizar a eficiência de memória em tempo real sem ferramentas externas:
- Abra o arquivo
test-client.htmlno seu navegador (arraste e solte o arquivo). - Rode o script de upload no seu terminal:
npm run upload. - Acompanhe a atualização do dashboard via Server-Sent Events enquanto o uso de RAM permanece estável.
⚠️ Limitações Conhecidas
| Limitação | Solução na v2.0 |
|---|---|
| Single Node | Funciona em um único servidor. Para processamento distribuído, precisaríamos enviar o arquivo para o Amazon S3 primeiro e acionar um Worker SQS. |
👨💻 Autor
Gérson Resplandes Backend Engineer focado em Performance e Arquiteturas de Stream.